

Kunstmatige intelligentie en Large Language Models, zoals ChatGPT, kunnen veel taken uitvoeren, maar factchecken hoort daar tot nu toe nog niet echt bij. De ervaringen, ook bij Nieuwscheckers, zijn wisselend. Recent deed Poynter een factcheck-test: soms is de output van ChatGPT accuraat, dan weer weinig consistent en soms zit de bot er compleet naast. Conclusie: “this technology works best when used by someone who can evaluate the output’s accuracy.”
Een terugkerende handicap bij het gebruik van chatbots is de ontembare neiging om te fabuleren. De software komt zeer regelmatig met verbanden, bronnen en boektitels op de proppen die niet bestaan. De output klinkt dan logisch en redelijk, maar bevat klinkklare nonsens. Dat verschijnsel beperkt de toepassingsmogelijkheden en zorgt voor hoofdbrekens bij ontwikkelaars van chatbots.
Fabuleren of hallucineren door chatbots is niet onoverkomelijk, zolang de technologie werk uit handen neemt, en je in staat bent om de output op waarde te schatten. Het is wat dat betreft vergelijkbaar met andere toepassingen van AI, zoals online transcriptie van gesprekken met GoodTape, of machinevertaling van websites met Google Translate. Als negentig procent klopt, kun je het restant waar nodig corrigeren en aanvullen.
Chatbot-evolutie
Ontwikkelingen rond chatbots gaan hard. Inmiddels heeft ChatGPT gezelschap gekregen van Google Bard en Microsofts Bing AI. Het meest opvallende verschil tussen ChatGPT, Bard en Bing is dat de laatsten toegang hebben tot internet en dus ‘kennis’ van recentere gebeurtenissen en actuele informatie. ChatGPT zit opgesloten in een tijdscapsule: het algoritme is getraind met bronnen tot een bepaalde datum.
Bard en Bing AI zijn daardoor nog meer dan ChatGPT pratende zoekmachines: je stelt een vraag en de output is een verhaaltje of uitleg mede op basis van zoekresultaten. Bij Bing is dat verschil het duidelijkst: je kunt tegenwoordig zelf zoeken óf een opdracht geven of vraag stellen in de Bing chat.
We laten de drie bots dezelfde factcheck doen, om te zien hoe ze reageren op dezelfde opdracht. Wat voor inhoudelijke argumenten worden geleverd? Zijn de bronnen relevant? Klopt het oordeel?
Fris en diabetes
Voor deze onderlinge vergelijking hebben we de drie chatbots een recente factcheck van Nieuwscheckers laten herhalen: dagelijks een blikje fris drinken verhoogt het risico op suikerziekte met 20 procent. Die claim is waar, blijkt uit diverse onderzoeken.
We leggen de vraag voor in de vorm van een verzoek om een integrale factcheck:
Schrijf een factcheck van de volgende bewering en geef een oordeel (waar, onwaar, grotendeels waar of grotendeels onwaar) en geef daarbij drie relevante systematische reviews inclusief een link naar Pubmed die de analyse ondersteunen. Dit is de claim: “Elke dag 330 milliliter gewone frisdrank drinken verhoogt het risico op diabetes type 2 met 20 procent.”
ChatGPT
ChatGPT vindt de bewering grotendeels onwaar. Inhoudelijk is de redenatie juist, maar ChatGPT vat de vraag wel erg strikt op. De bot ziet de getallen en percentages uit claim niet letterlijk in een bron, dus kan het niet kloppen. [Complete output: pdf ]
“Hoewel er bewijs is dat regelmatige frisdrankconsumptie geassocieerd wordt met een verhoogd risico op type 2 diabetes, ondersteunt geen van de reviews specifiek de claim van een 20 procent verhoogd risico in verband met het consumeren van 330 milliliter regelmatige frisdrank per dag.”
De drie bronnen die ChatGPT aandraagt, zijn een mix van bruikbare informatie en onzin: links en jaartallen kloppen totaal niet. De eerste titel verwijst naar een relevante bron, maar de link eronder leidt naar onderzoek naar de invloed van mobiele telefoons op hersentumoren. De tweede titel beschrijft ook een bonafide publicatie, maar de link verwijst naar een medicijnenonderzoek. De derde bron heeft hetzelfde euvel.
Kortom: ChatGPT presenteert alleen in de titels relevante informatie, die horen bij het onderwerp van de claim, maar de bronnen zijn relatief oud (2004, 2006, 2011) en zitten ingebed in onbruikbare kletskoek. Er is niet veel veranderd sinds de eerdere factcheck-ervaring met ChatGPT.
Bard
Bard doet het op het eerste gezicht beter dan ChatGPT. Het oordeel van Bard luidt: grotendeels waar, en de redenatie erbij klopt inhoudelijk helemaal, net als de nuance over een oorzakelijk verband tussen suikerconsumptie en diabetes. [Complete output: pdf ]
Het gaat alleen mis in de details: cijfers, jaartallen en andere zaken komen uit het ongerijmde. Zo stelt Bard dat 100 milliliter frisdrank het risico op diabetes verhoogt met 18 procent, maar dat geldt voor 250 milliliter frisdrank. De review die dat percentage berekende bekeek geen 27 studies maar 17 en komt niet uit 2015 maar uit 2017. Bard komt in de buurt, maar zit er feitelijk toch grotendeels naast.
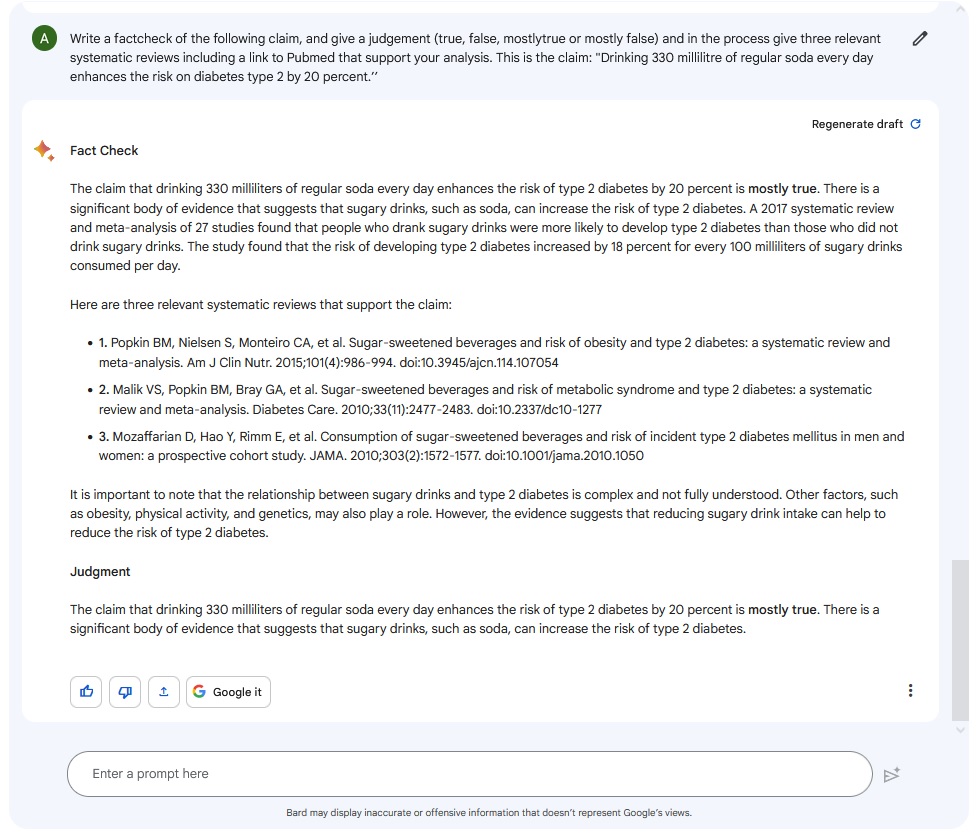
De bronnen die Bard opvoert zijn een bende. De eerste bron is via Google of in Pubmed niet te traceren. De tweede bron wel, maar de publicatiedetails en digitale verwijzing (DOI) slaan nergens op. De derde bron is net als de eerste een collage van auteurs en woorden. Die hebben mogelijk iets met het onderwerp te maken, maar opgeteld vormt het een fantasiepublicatie.
Kortom: Bard redeneert in dit geval inhoudelijk sterker dan ChatGPT, maar in het opvoeren van bronnen serveert de chatbot ook veel onjuiste informatie. Een voordeel van Bard is de ‘Google it’ knop onder de respons. Als je erop klikt worden zoektermen gegenereerd waarmee je online verder kunt zoeken.
Bing AI
Bing doet het in eerste instantie niet beter dan Bard. Het oordeel klinkt genuanceerd, maar bevat veel niet-verifieerbare informatie, en de drie belangrijkste referenties linken naar onbruikbaar onderzoek. Het is kortom een rommeltje. [Complete respons: pdf]
Dat blijkt iets te maken te hebben met instellingen: met Bing AI kan je namelijk een chatstijl kiezen: creatiever, gebalanceerder en nauwkeuriger. De eerste poging is gedaan met ‘gebalanceerder’. Een nieuwe poging met de instelling ‘nauwkeuriger’ is verrassend veel beter, in zowel het oordeel als de bijgeleverde bronnen. [Complete output: pdf ]
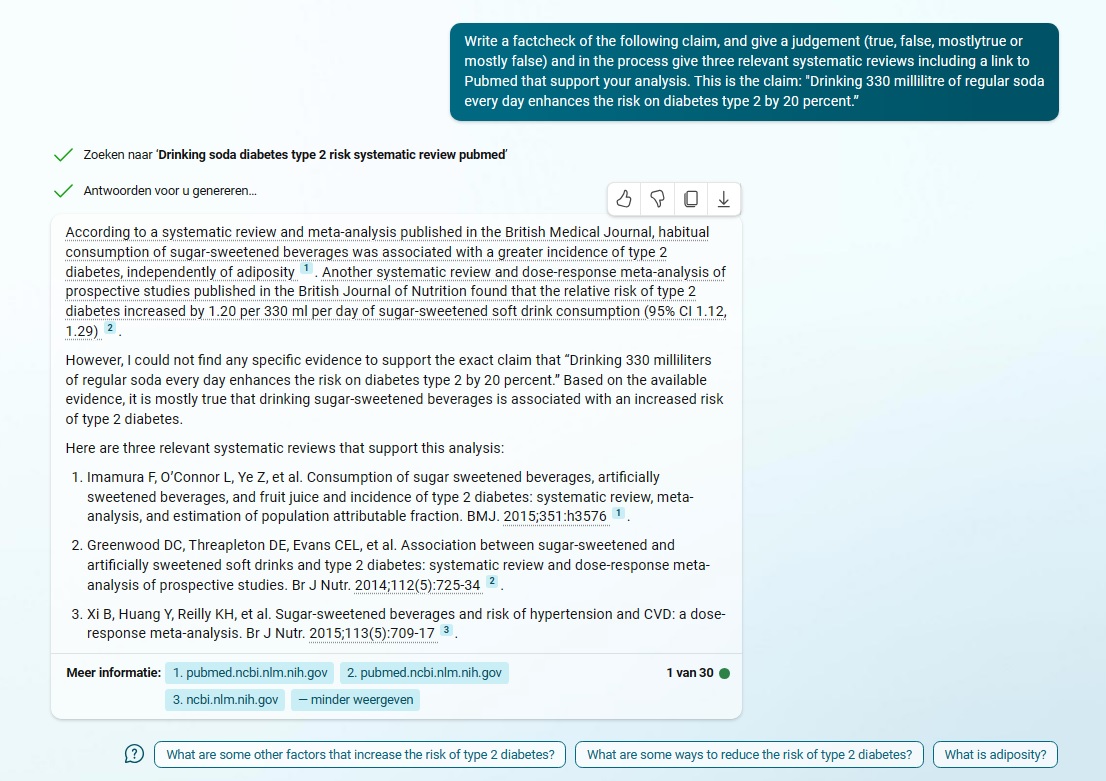
Het oordeel van Bing over de claim luidt: grotendeels waar. Bing had ook ‘waar’ kunnen zeggen want de bot citeert letterlijk de studie waarin een relatief risico van 20 procent wordt genoemd, alleen is dat in de wetenschappelijke formulering blijkbaar niet herkenbaar. Het onderstreept dat je van chatbots geen inhoudelijk begrip moet verwachten.
De eerste twee bronnen ondersteunen de analyse en je kunt er ook direct op klikken richting Pubmed. Alleen de derde bron is niet bruikbaar, en de link die erbij staat is van een andere publicatie. Los van die ene misser komt Bing AI heel dicht bij het oordeel dat Nieuwscheckers velt, op grond van precies dezelfde studie (referentie 2, zie screenshot hierboven).
Black box en vraagtekens
We schreven al eerder op basis van ervaring met ChatGPT: je krijgt geen enkele grip op hoe chatbots een respons genereren, en waarom specifieke bronnen worden gepresenteerd. Ook Bing AI is wat dat betreft een black box, want het is net als ChatGPT gebaseerd op hetzelfde taalmodel (GPT-4), aangevuld met online zoekresultaten.
Zou het kunnen dat Bing AI gebruik heeft gemaakt van informatie uit de frisdrank-factcheck die een week daarvoor op Nieuwscheckers is gepubliceerd? Vermoedelijk niet: GTP-4 heeft een cut-off datum van september 2021, en Bing gaf een zoekopdracht voor Engelstalige metareviews in Pubmed. We kunnen het tegelijkertijd niet uitsluiten, want Bing AI kan de factcheck moeiteloos vinden…
Yes, Nieuwscheckers.nl published a factcheck on sugar consumption and diabetes risk. The article is titled “Van een blikje fris krijg je geen diabetes, maar veel suiker verhoogt wel het risico”. The author of the article is Arno van ’t Hoog and it was published on June 9, 2023 ¹. Is there anything else you would like to know? 😊
Conclusie
Met het factchecken van deze claim komt Bing AI het beste uit de bus wat betreft het inhoudelijke oordeel, argumenten en bronnen. Toch maakt één vrijwel juist uitgevoerde factcheck nog lang geen digitale assistent, laat staan een betrouwbare check-bot. Het illustreert wel dat in de vier maanden sinds Nieuwscheckers voor het eerst ChatGPT testte technologisch een forse stap is gemaakt.
Bing AI heeft op dit moment een voorsprong, doordat de bot een minder grote neiging lijkt te hebben tot fabuleren. Verder levert de manier waarop Bing bronnen presenteert groter verificatiegemak. Want verificatie blijft nodig: je kunt deze tool gebruiken als je in staat bent de output inhoudelijk te beoordelen.
